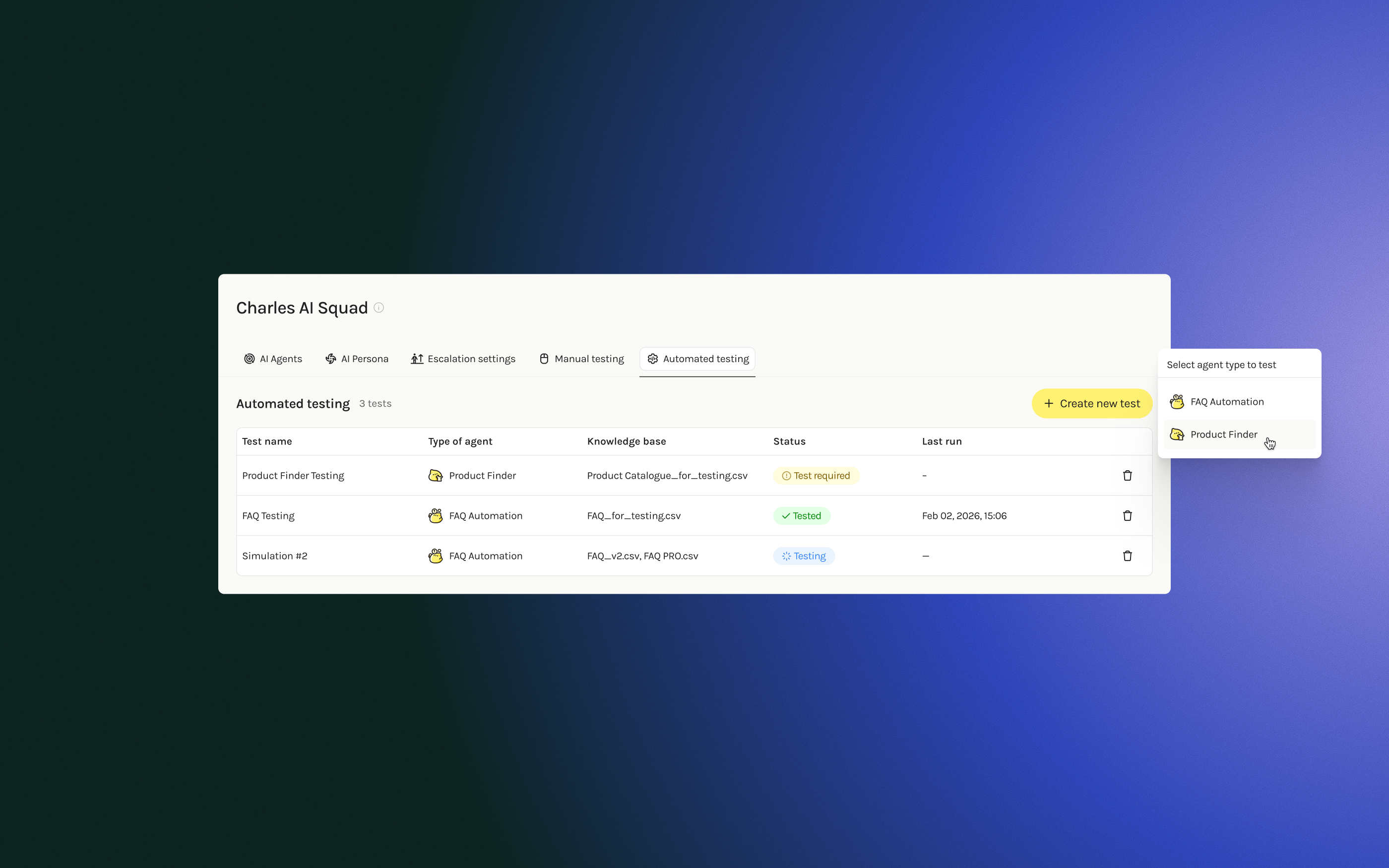
AI Agent Automated Testing for charles
charles helps e-commerce brands deploy AI agents on WhatsApp: FAQ agents for simple Q&A and Product Finder agents that recommend products by asking clarifying questions. Currently there's no structured way to validate if the agent is ready to launch.
📦 Deliverables
- End-to-end flow design for AI agent testing feature
- User research and validation interviews
- Interactive prototypes for stakeholder review
🔍 Problem
After setting up an AI agent, clients spent hours manually testing on WhatsApp instead of using the platform, with no structure or objective criteria for readiness. They'd fixate on specific edge cases while missing broad performance gaps. Launches were delayed indefinitely with no clear path forward.
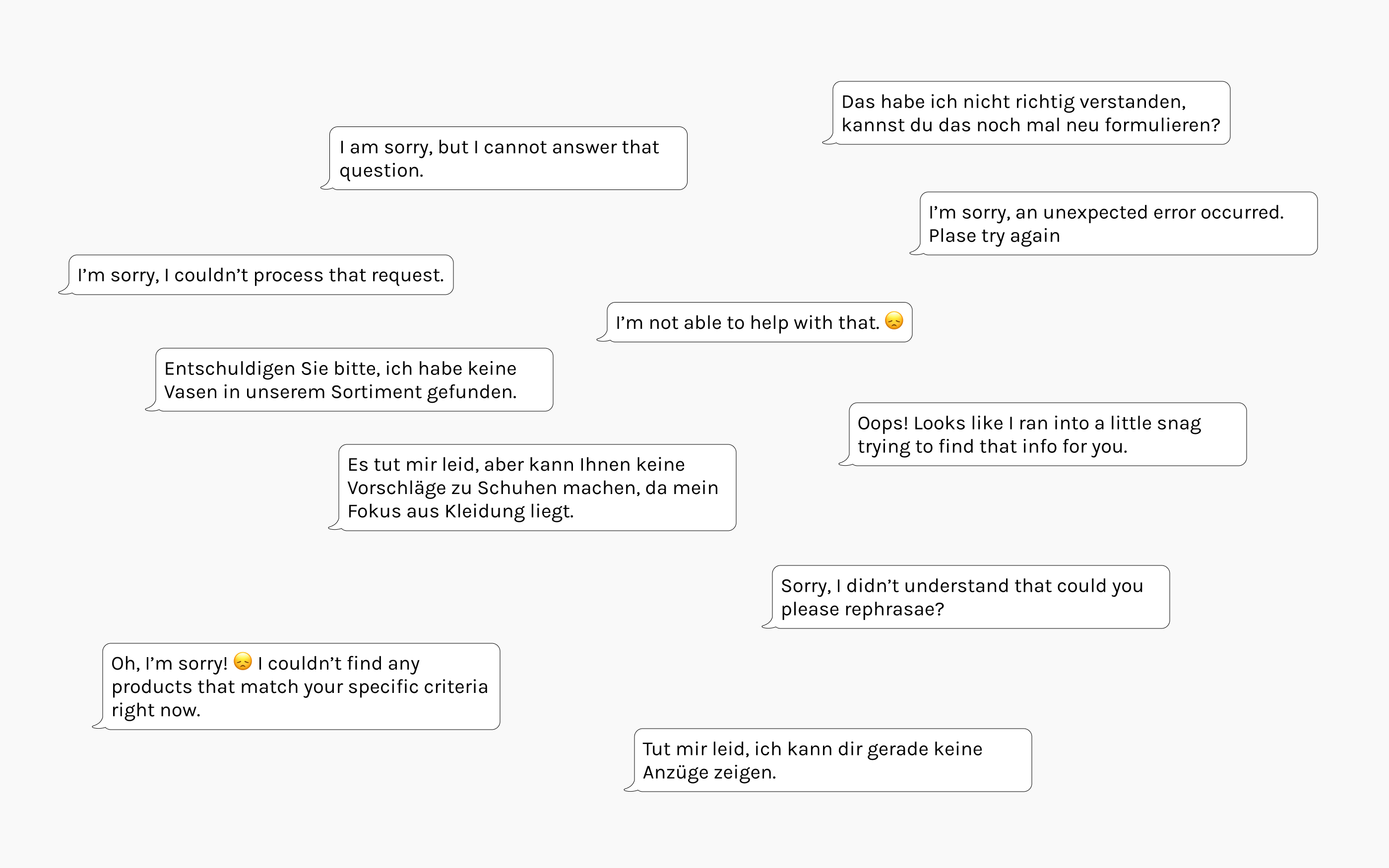
🔧 Approach
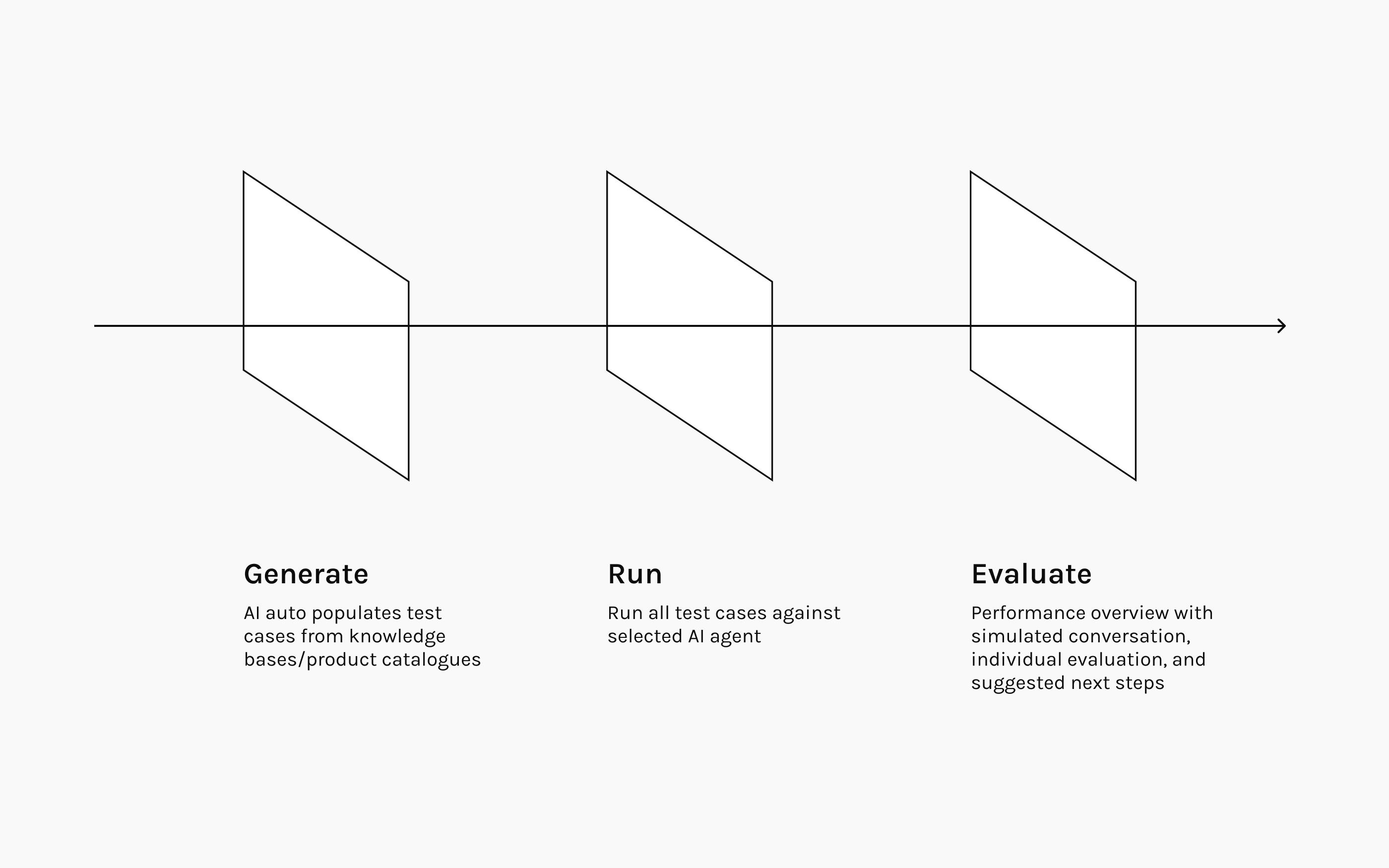
I designed an automated testing environment built around three core capabilities: generate test cases from knowledge bases and catalogs, run them against the full agent setup, and evaluate performance with a readiness overview.
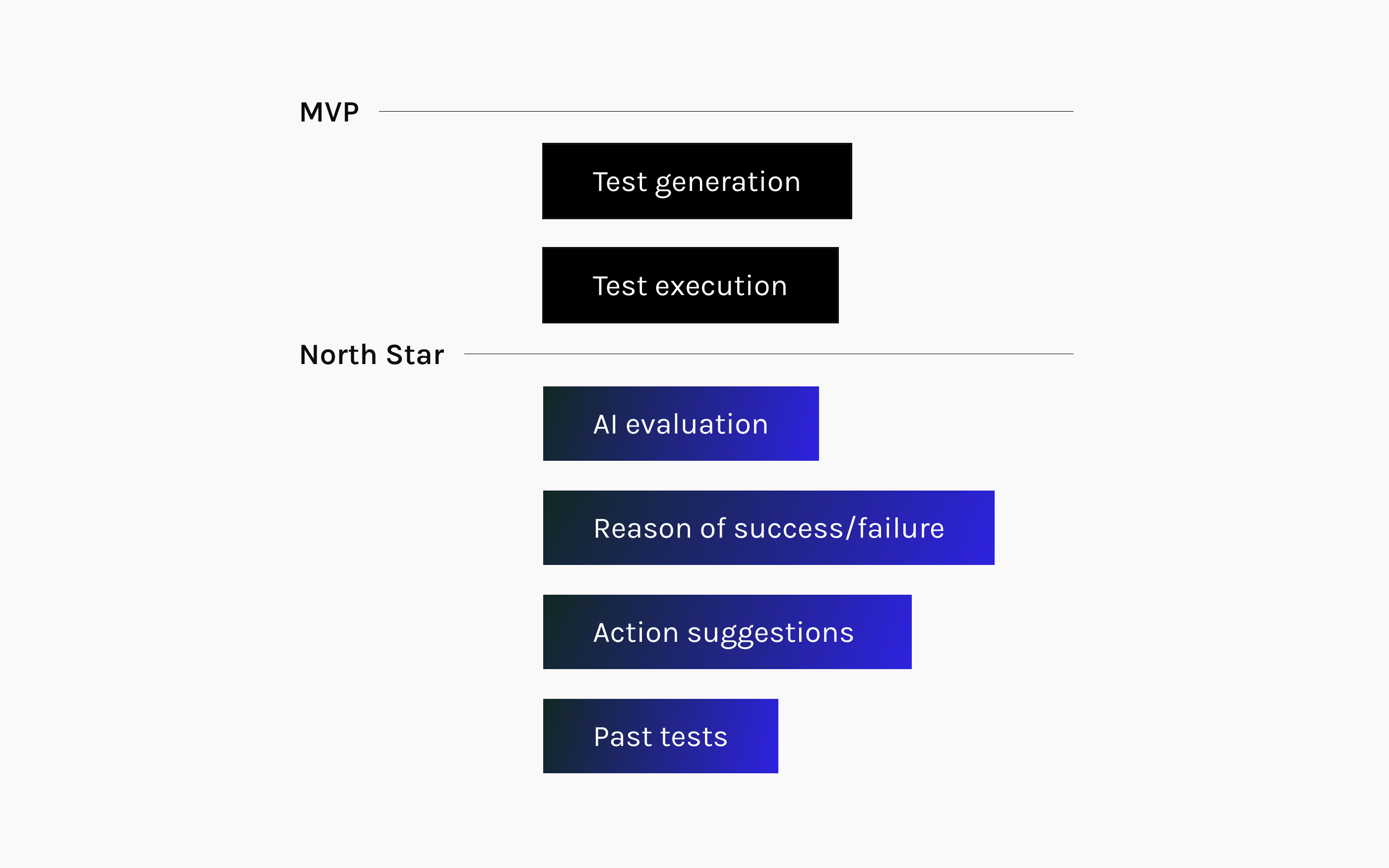
We defined two scopes: North Star includes AI evaluation and action suggestions, while MVP focuses on test generation and execution only due to engineering constraints.
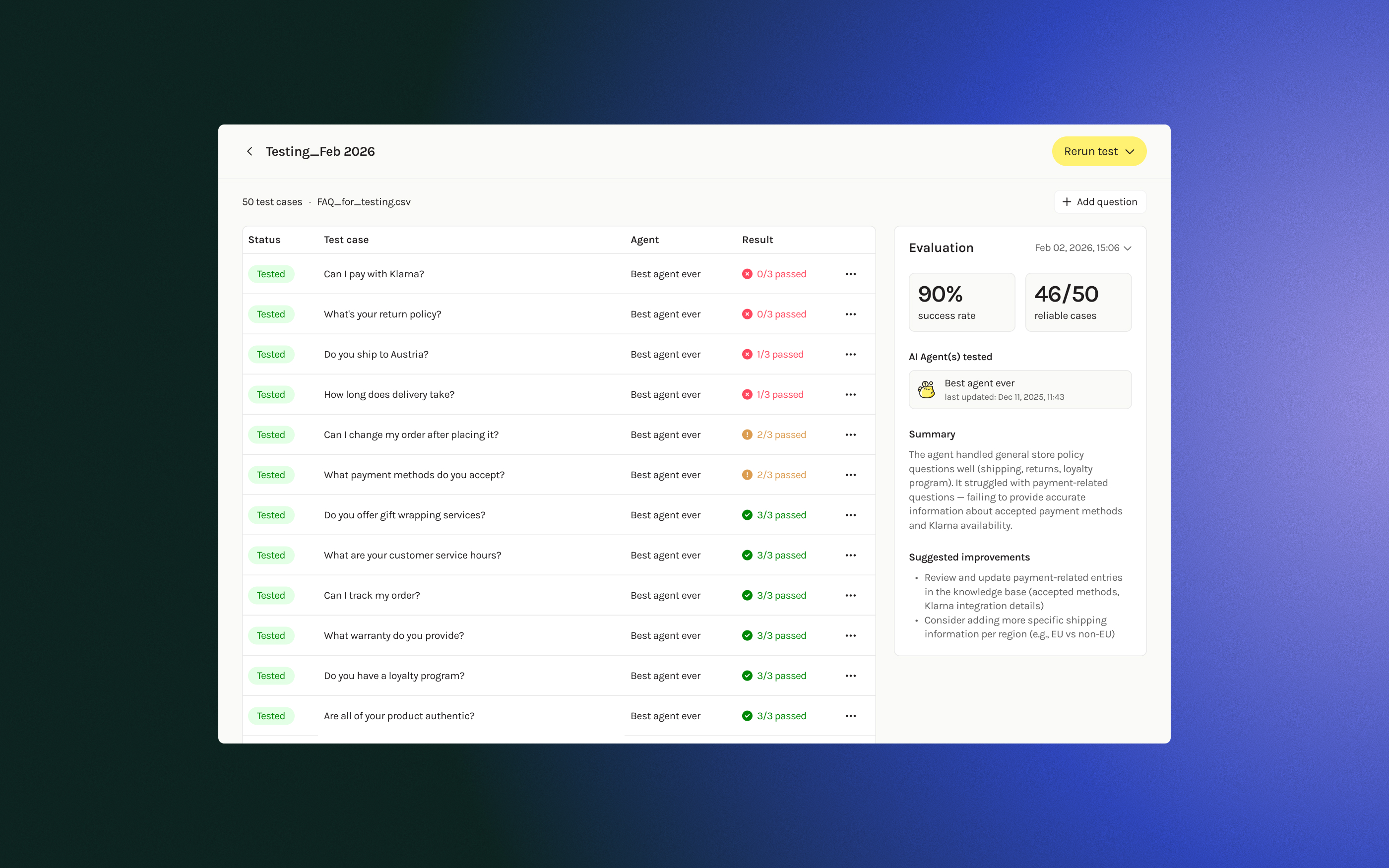
💡 Solution: FAQ Agent
Starting with FAQ agents, I designed a flow where clients auto-generate test questions, run them against their agent, and review the conversations.
During discussions, the inherent randomness of AI responses was surfaced: the same question can produce different answers each time. To address this, I proposed running each test 3 times and showing all runs, letting clients assess consistency themselves. Three runs gave enough confidence without excessive cost.
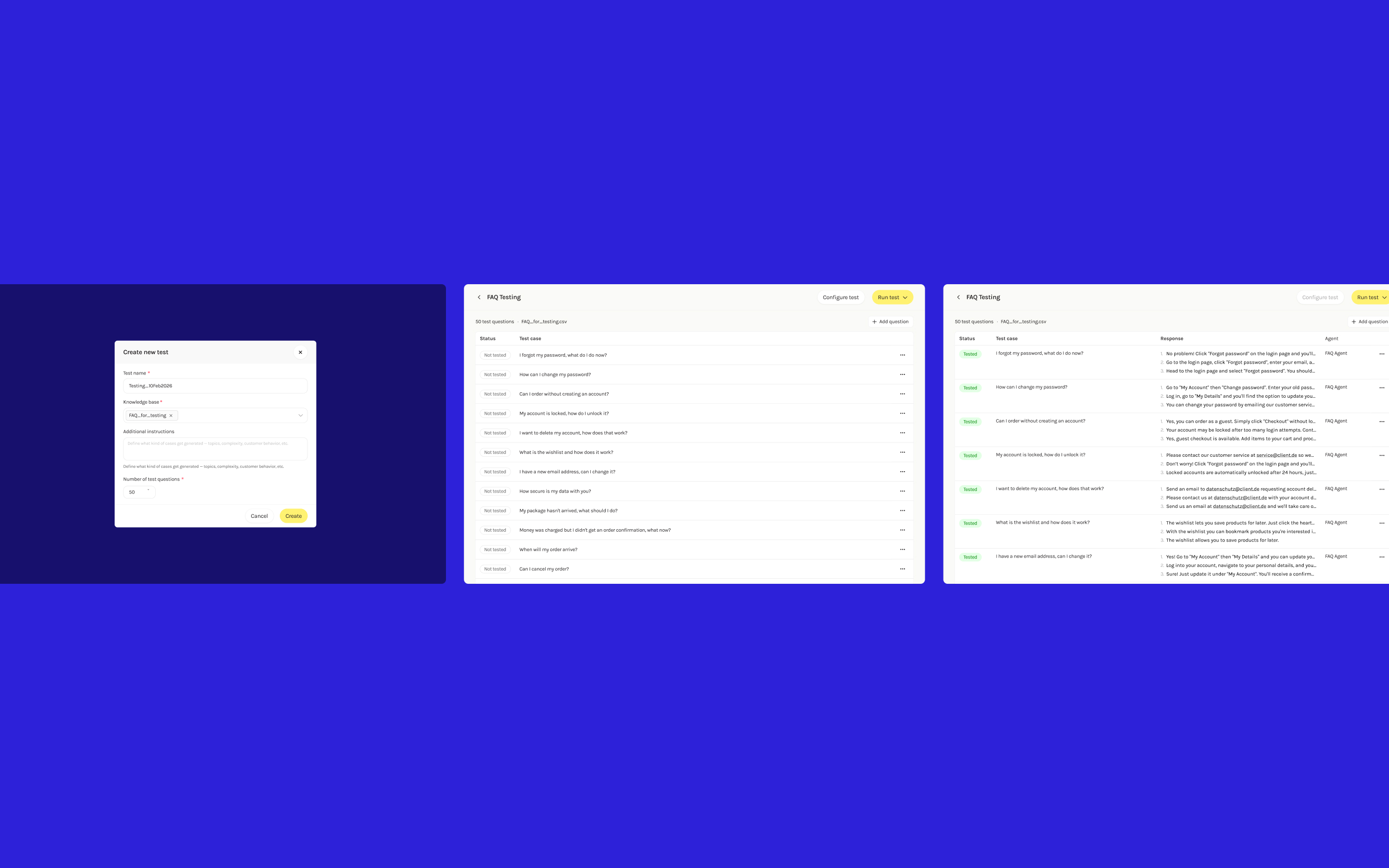

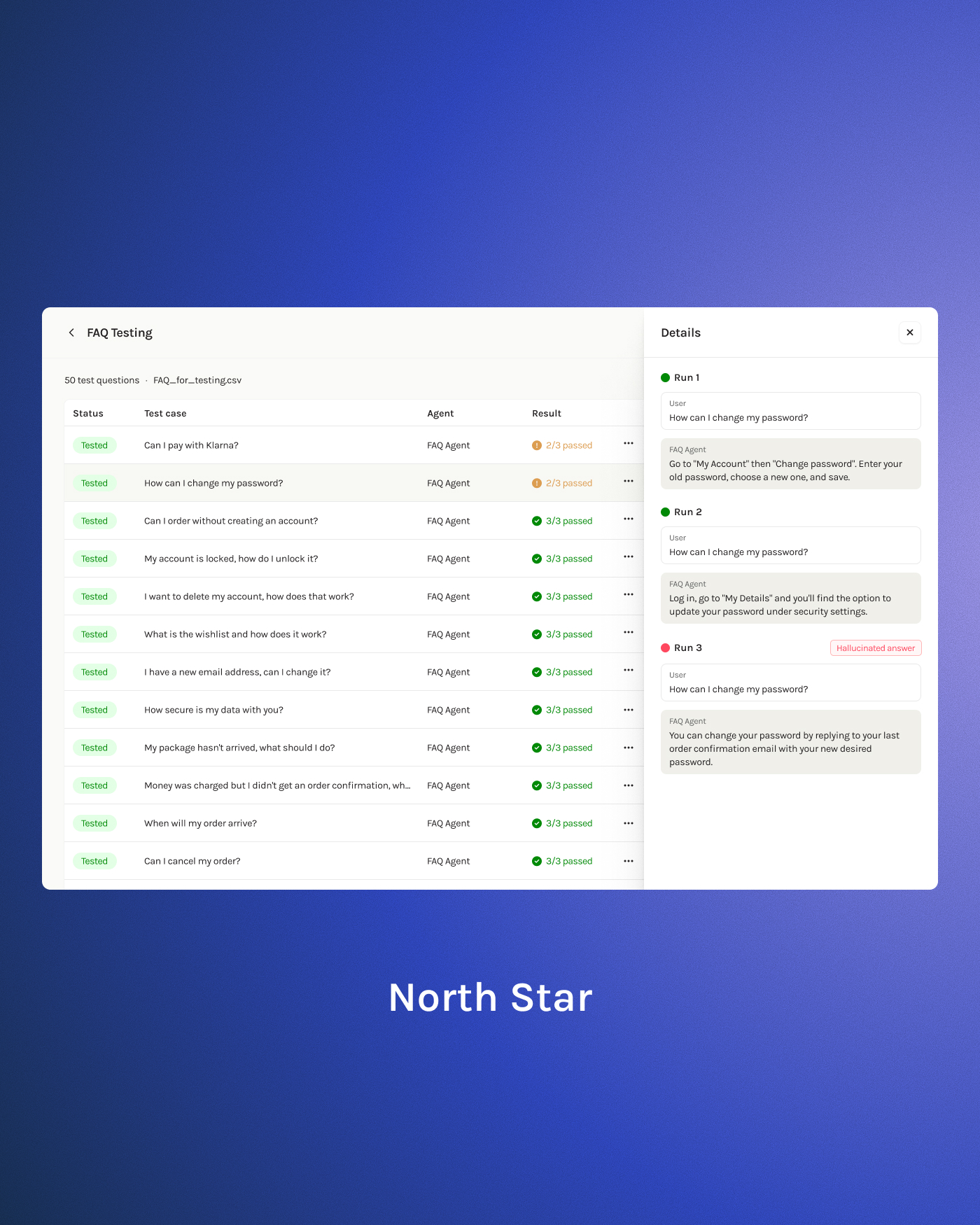
User testing validated that seeing "2/3 passed" felt more reassuring than an aggregate percentage, and confirmed they'd switch from manual phone testing back to the platform.
🔦 Evolution: Product Finder
A major e-commerce client using Product Finder revealed the simplified setup wasn't structured enough. Multi-turn conversations need varied customer behaviors, but the freeform "additional instructions" field gave no guidance.
I redesigned with explicit structure that accommodates different client needs and sets the foundation for future evaluation. Conversation Style chips simulate how different end users communicate, testing how the AI responds and filters products accordingly. Scenario Complexity presets adjust how clearly defined or ambiguous the customer's criteria are—keeping the goal consistent while varying how the AI must interpret subjective language.
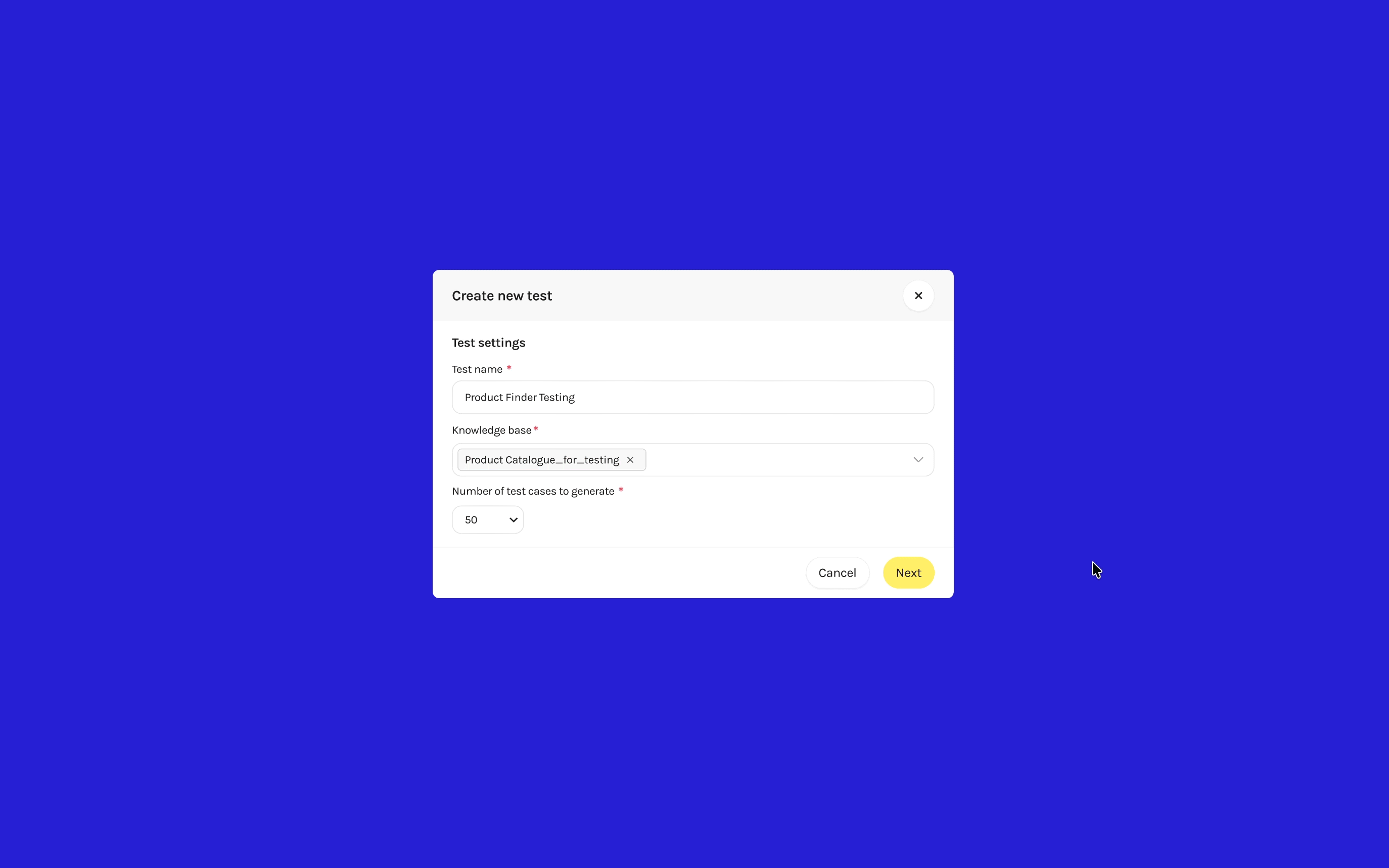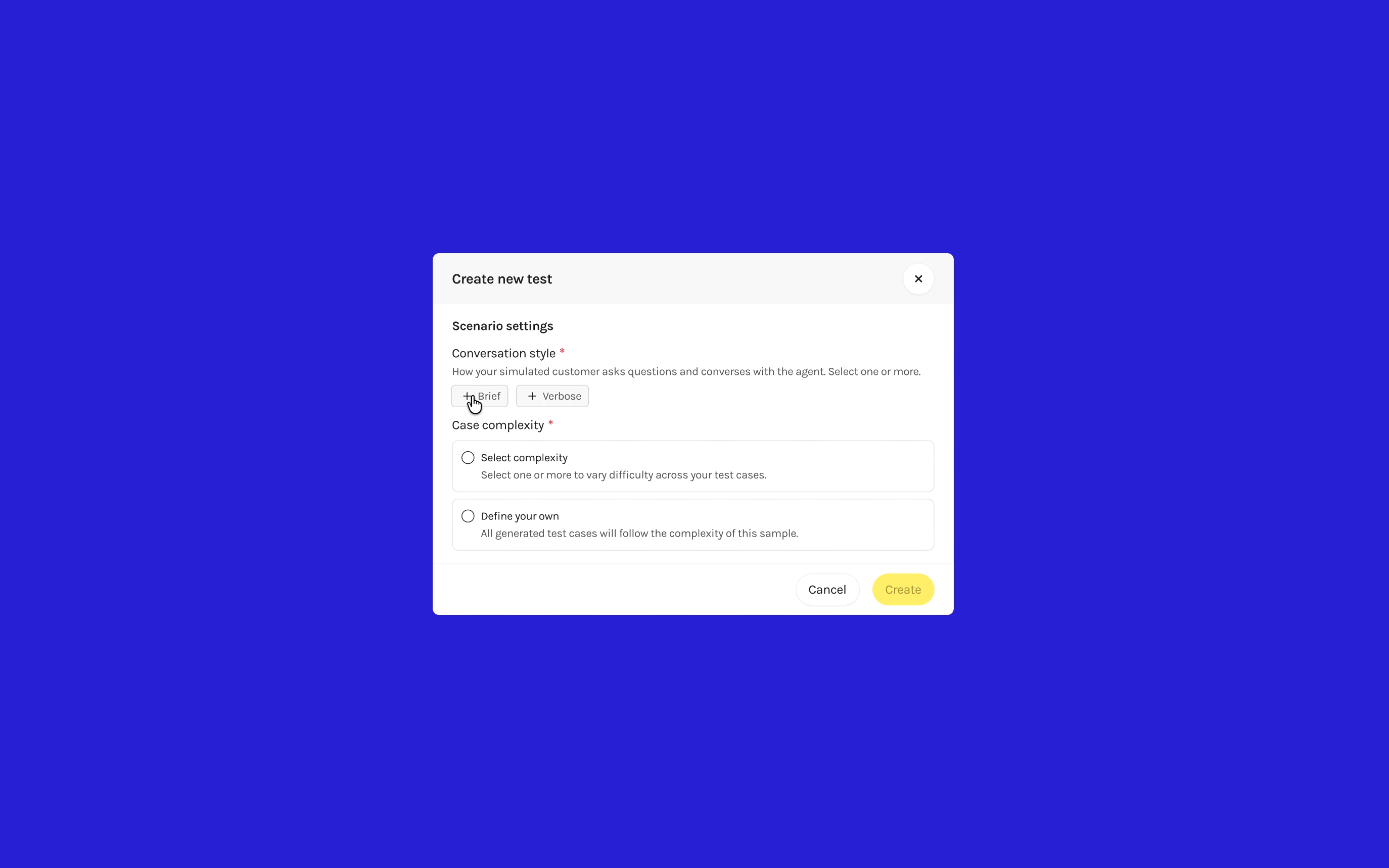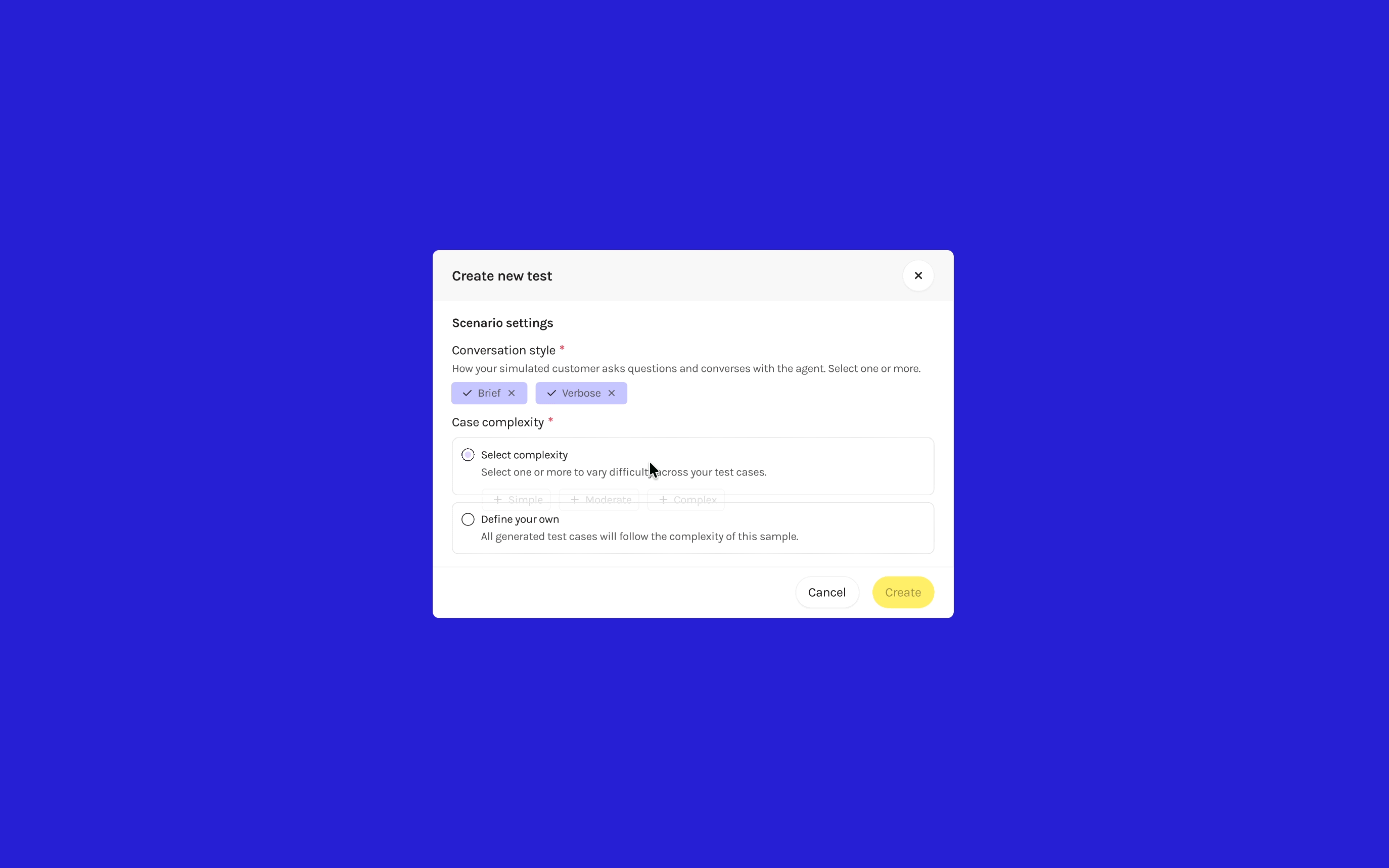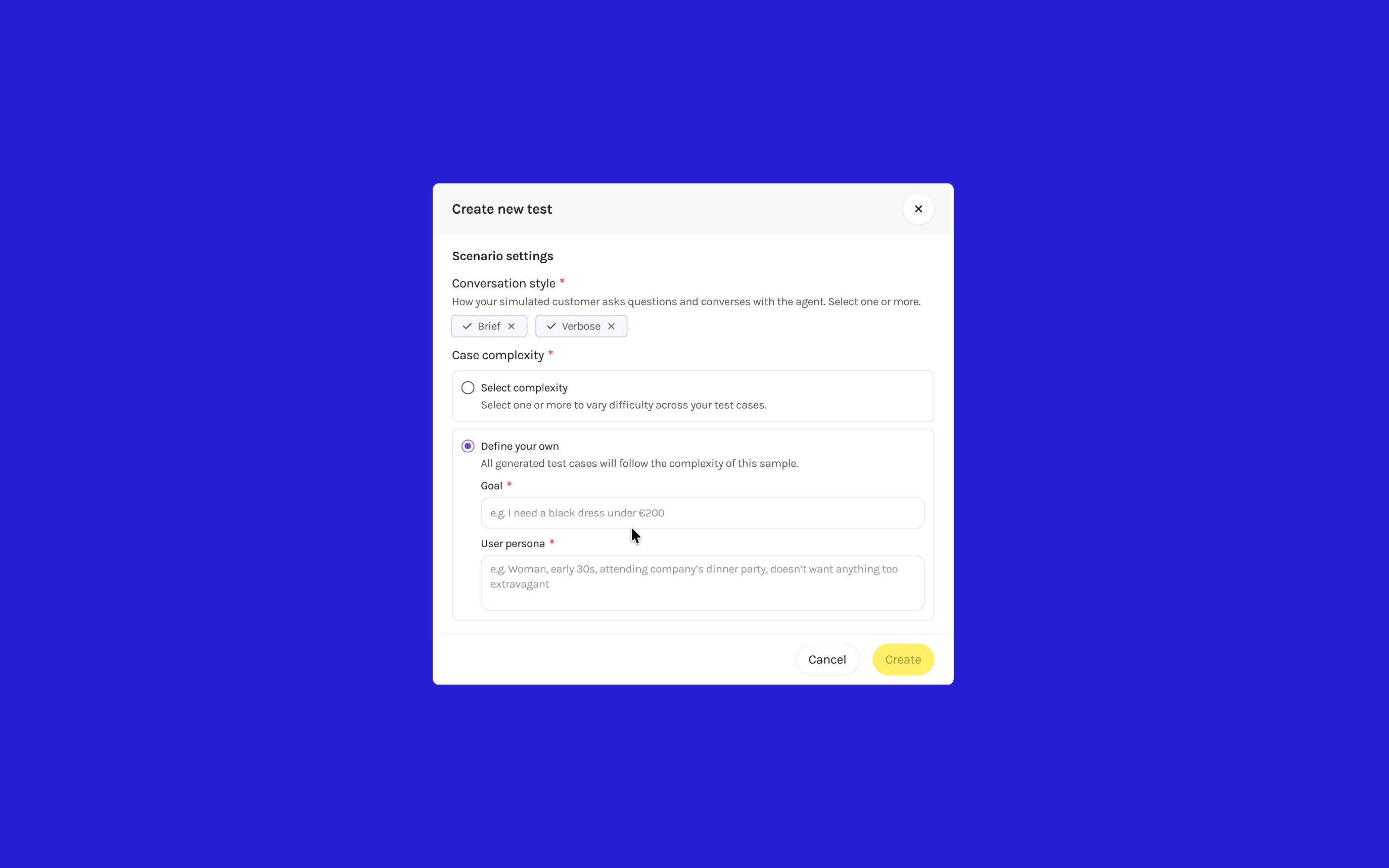
For clients who know exactly what they want to test, a "Define your own" option lets them provide a custom Goal and User Persona directly. This gives structure to clients unfamiliar with prompting AI while giving control to more demanding users who need specific edge cases.
🌱 Outcome
The testing environment is currently being developed and rolled out in phases. FAQ testing is launching first, with Product Finder following. By designing two entry points from the start—separating FAQ and Product Finder at test creation—each agent type has tailored setup and results views that accommodate their different needs. This enabled a gradual rollout, allowing clients to benefit from structured testing sooner while we continue building for more complex use cases.